3、SQLDatabaseChain实现原理
简介
在前一篇文章中,我们基于LangChain成功地实现了对TPC-DS数据库的智能问答。本章将详细探讨SQLDatabaseChain的实现原理,首先介绍LangChain调试方法的启用,以获取SQLDatabaseChain执行过程中的调试信息。接下来,我们将通过分析调试信息的结果,深入阐述SQLDatabaseChain数据库交互的具体实现原理。
Langchain调试启用
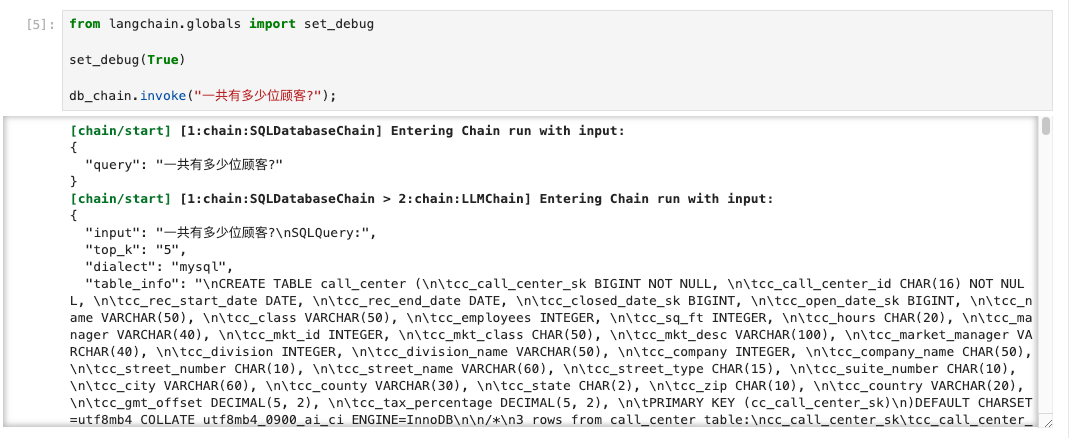
Langchain提供了set_debug方法用于在运行Python脚本和JupyterNotebooks时打印Chain运行中的详细调试信息。 通过此方法可以设置全局的调试(debug)标志,这将导致所有支持回调的 LangChain 组件(链、模型、代理、工具、检索器)打印它们接收的输入和生成的输出。这是最详细的设置,将完整记录原始输入和输出。
from langchain.globals import set_debug
set_debug(True)
如下图所示,一旦启用了debug模式LangChain将详细记录并打印出每一步执行过程的调试信息:
SQLDatabaseChain实现原理
执行流程
在LangChain框架中,“Chain”概念指的是一系列组件或代理(Agent)构建的系统,这些环节协同工作,以完成特定的任务。SQLDatabaseChain特别针对SQL数据库交互场景而设计,能够将用户的自然语言输入转化为数据库查询,执行这些查询,并将�结果以自然的形式反馈给用户。
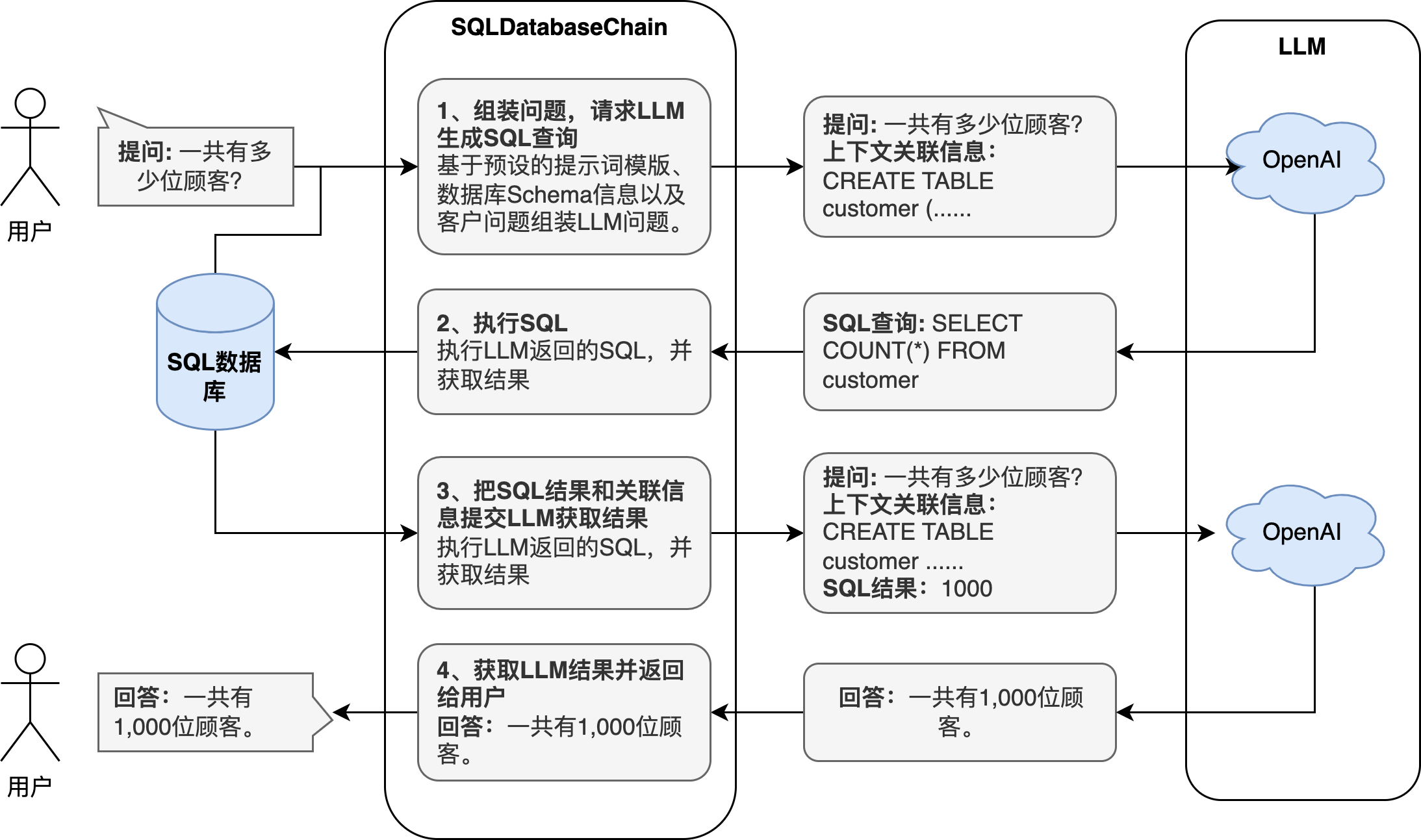
下图呈现了SQLDatabaseChain的执行流程图,整个执行过程分为四个步骤:
- 组装提问信息,请求LLM生成SQL查询语句
基于内置预设的提示词模版组装LLM的提交内容,内容中主要包括用户的问题、数据库Schema等上下文关联信息,以便LLM能够更准确的生成SQL查询语句。内容组装完成之后就会被提交到LLM API执行,并获取结果返回。 - 执行SQL查询
SQLDBChain在数据库中执行LLM返回的SQL语句并获取结果。 - 把SQL执行结果和关联信息再次提交到LLM生成最终结果
把SQL执行的结果追加到之前提交到LLM后,并且再次提交到LLM。 - 获取LLM结果并返回给用户
最后,SQLDatabaseChain获取LLM的最终结果并将其返回给用户。
SQLDatabaseChain内置提示词模版
SQLDatabaseChain内置的提示词模板的主要目的是为了引导模型如何将自然语言的问题转化为SQL查询,并指导模型如何处理查询结果以提供准确的答案。这一提示词模板主要涵盖以下关键信息:
- 角色设定: 将语言模型定位为MySQL数据库专家,使其能够理解和处理与MySQL数据库相关的问题。
- 任务执行流程: 在任务的执行过程中,首先对用户输入的问题进行解析,以生成相应的SQL查询。接着,通过执行生成的SQL查询,获取数据库的��结果,并据此形成最终的答案返回给用户。
- 生成SQL查询要求: 提示词明确要求模型在生成SQL查询时考虑多方面的因素,如限制查询字段、限制数据返回数量等。这有助于确保生成的查询是精准而又高效的。
此外,提示词模板包括三个变量,分别为{input}、{top_k}、{table_info},它们分别代表用户的输入问题、返回数据的限制以及数据库的详细信息。
You are a MySQL expert. Given an input question, first create a syntactically correct MySQL query to run, then look at the results of the query and return the answer to the input question. Unless the user specifies in the question a specific number of examples to obtain, query for at most
{top_k}results using the LIMIT clause as per MySQL. You can order the results to return the most informative data in the database. Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in backticks (`) to denote them as delimited identifiers. Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table. Pay attention to use CURDATE() function to get the current date, if the question involves "today".Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer hereOnly use the following tables:
{table_info}Question:
{input}
SQLDatabase
SQLDatabase是一种实用的工具类,专门��设计用于协助链式操作获取数据源的详细信息。其功能包括提供数据库中表的清单、每张表的数据结构以及示例数据。
通过访问SQLDatabase的table_info属性,我们能够观察到该属性存储了数据库中所有表的数据定义语言(DDL)信息,同时还包含每张表的三条示例数据。ChatGPT之所以能够生成准确的SQL查询是因为它依赖于SQLDatabase所提供的丰富元数据信息。
CREATE TABLE call_center (
cc_call_center_sk BIGINT NOT NULL,
cc_call_center_id CHAR(16) NOT NULL,
cc_rec_start_date DATE,
......
PRIMARY KEY (cc_call_center_sk)
)COLLATE utf8mb4_0900_ai_ci DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB
/*
3 rows from call_center table:
cc_call_center_sk cc_call_center_id cc_rec_start_date cc_rec_end_date cc_closed_date_sk cc_open_date_sk cc_name cc_class cc_employees cc_sq_ft cc_hours cc_manager cc_mkt_id cc_mkt_class cc_mkt_desc cc_market_manager cc_division cc_division_name cc_company cc_company_name cc_street_number cc_street_name cc_street_type cc_suite_number cc_city cc_county cc_state cc_zip cc_country cc_gmt_offset cc_tax_percentage
1 AAAAAAAABAAAAAAA 1998-01-01 0000-00-00 0 2450952 NY Metro large 2 1138 8AM-4PM Bob Belcher 6 More than other authori Shared others could not count fully dollars. New members ca Julius Tran 3 pri 6 cally 730 Ash Hill Boulevard Suite 0 Midway Williamson County TN 31904 United States -5.00 0.11
......
*/
CREATE TABLE catalog_page (
cp_catalog_page_sk BIGINT NOT NULL,
cp_catalog_page_id VARCHAR(16) NOT NULL,
cp_start_date_sk BIGINT,
......
PRIMARY KEY (cp_catalog_page_sk)
)COLLATE utf8mb4_0900_ai_ci DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB
/*
3 rows from catalog_page table:
cp_catalog_page_sk cp_catalog_page_id cp_start_date_sk cp_end_date_sk cp_department cp_catalog_number cp_catalog_page_number cp_description cp_type
1 AAAAAAAABAAAAAAA 2450815 2450996 DEPARTMENT 1 1 In general basic characters welcome. Clearly lively friends conv bi-annual
......
*/
结论
通过对SQLDatabaseChain运行机制的深入分析,揭示了SQLDBChain在数据访问和查询方面所展现的卓越能力。这一强大功能的实现建立在ChatGPT对数据库元数据的理解和SQL生成的卓越能力之上,实现了以自然语言为基础的数据访问。对于那些不具备SQL查询技能的个体而言,SQLDBChain不仅令其获得了一项高效且强大的工具,还使其能够通过自然语言进行数据分析,极大地提升了数据访问的便捷性。
然��而,SQLDatabaseChain在实际生产环境中存在一些限制,使其无法作为一个可用的生产工具。以下是这些限制的详细列举:
-
SQLDatabase一次性读取DDL信息和示例数据
SQLDatabaseChain的机制包括一次性读取所有数据库表的DDL信息和示例数据。在生产数据库中,通常存在大量数据库表,这种一次性读取的做法可能导致一次LLM请求消耗大量的token数,可能超出可提交的token数限制,或者导致成本过高。 -
元数据信息不完善导致推理错误
如果数据库表的字段命名不规范,例如出现拼音或一些代码字段,并且没有足够的备注信息,可能导致推理错误。完善的元数据信息对于正确的推理至关重要。 -
复杂关系模型的理解挑战
在复杂的数据库设计中,ChatGPT在理解关系模型方面可能面临挑战,因此可能需要额外的提示信息或少量样本用于微调数据库以确保准确理解复杂的关系。 -
执行流程简单,不具备复杂推理能力
SQLDBChain的执行流程是基于用户的问题生成一条SQL查询语句,而在复杂的数据分析场景下需要进行推理和数据库进行多轮次的查询。这可能限制了其在处理复杂推理任务时的效果。