智能体和ReAct提示词
引言
在我们上一篇讨论中,我们探讨了智能体(Agent)的内部结构及其运行机制。接下来,我们将专注于阐述推动大型语言模型进行推理和思维过程的关键技术——ReAct提示词技术。
对于大型语言模型(LLMs)而言,处理复杂任务是一项具有挑战性的工作,特别是在面对超出其训练数据集知识范畴的情境时,它们可能会展现出幻觉现象,无法提供准确的回答。即便是在多个领域展现出优异性能的高级模型(如GPT-4),在这些推理任务上也可能遇到难题。
什么是ReAct
ReAct提示技术的核心在于整合推理(Reasoning)与行动(Acting)的功能,以增强模型在解决复杂任务时的能力,具体包括:
-
Re(Reasoning,推理)
此部分专注于模型的生成推理能力。它基于链式思考(chain-of-thought)的高级提示技术,旨在促使模型在执行任务时能够进行更为深入的思考和逻辑推理。核心要点在于通过这种方法,模型能够在其决策过程中更加有效地跟踪和更新自身的行动策略,并且能够更好地应对在执行过程中可能遇到的各种异常情况。 -
Act(Acting,行动)
此部分强调模型执行具体行动的能力,这些行动允许模型与外部资源(如知识库或环境)互动,从而获得额外的信息。在ReAct框架中,行动的概念超越了模型输出的直接结果,它指的是模型与外部世界交互的更为广泛��的行为,包括但不限于信息检索、执行特定任务的步骤等。此定义扩展了模型能力的理解,强调了模型在与外部世界互动时的动态能力和灵活性。
下面我们引用了论文《SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS》中的例子来展示在不同提示词指导下大型模型如何执行任务及其结果表现:
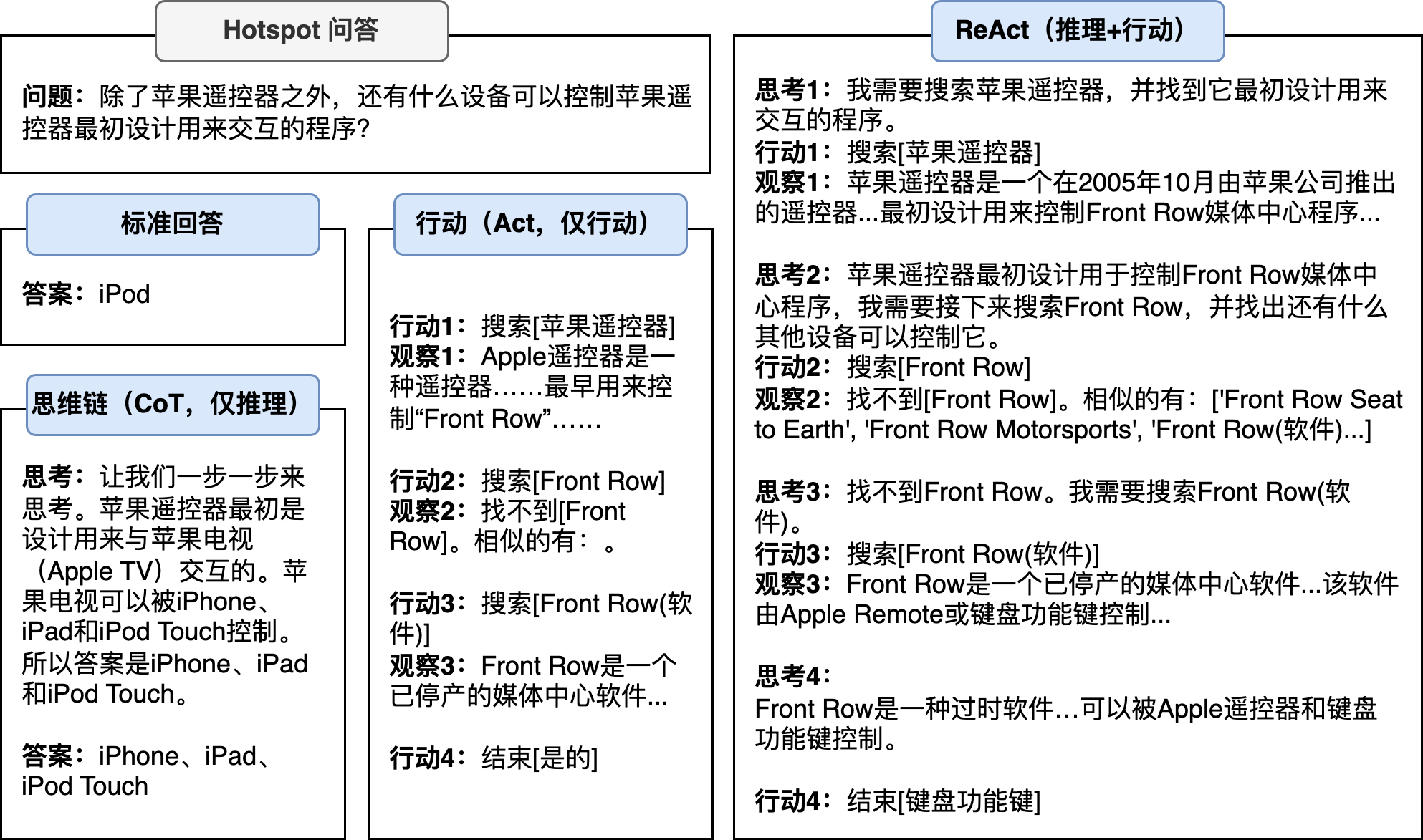
通过上述示例,我们能够对不同提示词技术及其产生的效果进行深入理解:
- 标准问答
在未提供特定提示的情况下直接向大型语言模型(LLM)提出查询,所得回答可能会缺乏精确性。这一现象的出现,通常可以归因于LLM对于所提出问题缺乏确切的知识基础。比如:由于Apple遥控器和iPod在语义上的紧密关联,模型可能会错误地将iPod识别为答案。 - 思维链(Chain-of-Thought)
即便应用了链式思考的范式以指导推理过程,如果基于的信息前提不准确,最终得到的答案依然会是错误的。这一点强调了准确、可靠信息作为推理和决策过程基础的重要性,无论推理方法的先进程度如何,都无法克服错误信息所带来的负面影响。 - 动作范式(仅动作)
尽管该范式通过特定的工具能够获取正确的信息,但若未能有效引导大型语言模型(LLM)执行深层次的推理,因此产生的结果依然可能是不准确的。这一观点凸显了在确保信息准确性的同时,对模型推理能力的有效指导同样至关重要。 - ReAct方法
该方法通过融合显式推理与具体行动,实现了对信息的持续获取与推理过程的不断精炼。这一方法使得智能体能够自主地工作直至正确答案。此过程不仅强调了信息收集的重要性,也突出了在动态环境中对策略进行迭代优化的必要性,从而为智能体提供了一种机制,以更有效地处理复杂问题并得出准确的结论。
ReAct提示词原理
思维链(Chain-of-Thought Reasoning)
ReAct的推理框架采纳了“思维链”(Chain of Thought, CoT)技术,这是一种针对大型语言模型(LLM)的高级提示工程策略。该技术的核心思想是向模型提供一组精心设计的示例,这些示例演示了如何通过一系列详细的逻辑步骤解决特定问题,即所谓的少量样本学习。紧接着,模型被引导使用这种同样的逻辑推理过程来处理一个全新的问题。通过这种方式,模型被训练以执行更加深入和复杂的中间推理步骤,从而提高其在解决需要高级逻辑推理能力的任务时的性能。
思维链技术通过促进模型进行更加细致和连贯的推理过程,大幅提高了模型在处理复杂逻辑问题时的准确率和可信度。这种方法不仅增强了模型对问题深层逻辑结构的理解,而且在面对复杂推理任务时,能够实现更为精确和深刻的逻辑分析,确保了推理过程的透明度和解决方案的可靠性。
下面是一个采用了思维链和未采用的对比示例,采用思维链技术的模型通过展示详细的逻辑推理过程,相比之下,未采用思维链技术的模��型直接给出答案,缺乏中间推理步骤,导致错误更难被识别和修正。总的来说,思维链技术为提高大型语言模型在复杂逻辑推理任务上的性能提供了一个有效途径。
| 标准提示词 | 思维链提示词 |
| 模型输入 提问: 罗杰有5个网球。他又买了两盒网球,每盒有3个网球。他现在有多少网球? 答案:答案是27。❌ | 模型输入 提问: 罗杰有5个网球。他又买了两盒网球,每盒有3个网球。他现在有多少网球? 答案:食堂原来有23个果,他们用掉20个,所以还有23-20=3个。他们又买了6个,所以现在有6+3=9个。答案是9。 |
ReAct提示词示例
尽管“思维链”(Chain of Thought, CoT)技术在提高逻辑推理准确性方面展现了显著潜力,它仍然面临着一定的局限性,特别是在处理基于错误或虚构“事实”进行推理时可能出现的“幻觉”现象。这种现象指的是模型可能依据不准确或不存在的信息构建其逻辑链,最终导致不正确的结论。
为了克服这一问题,ReAct在思维链的基础上引入了“行动范式”(Act),旨在通过综合利用内部知识库和获取的外部信息,大幅提升模型输出的可信度和基于事实的准确性。ReAct框架采用了一种迭代方法,该方法通过反复的“思考-行动-观察”循环来细化其推理过程。在每一次迭代中,模型不仅仅是生成思考和行动的方案,还整合了执行这些行动后所获得的观察结果,从而实现了对复杂情境的深入理解和分析。
通过这种方法,ReAct不仅增强了模型对信息的处理能力,还通过实时的反馈调整和优化了其推理过程,极大地增强了结果的准确性和可靠性。以下是一个典型的ReAct提示词模板,用以指导如何有效地应用这一框架:
Answer the following questions as best you can. If it is in order, you can use some tools appropriately.
You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do and what tools to use.
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
以下ReAct提示词模版的关键组成部分及其目的:
- 指令(Instruction)
这一部分向LLM提供了明确的指导,确保其准确理解所期望完成的任务。它为模型设定了操作框架和目标,确保其行动方向与预期目标一致。 - ReAct步骤(推理与行动)
详细规定了模型进行推理和采取行动的具体步骤。通过“思考(Thought)”、“行动(Action)”和“观察(Observation)”的迭代过程,模型不断优化其推理路径,直至达到解答问题的“最终答案(Final Answer)”。这一过程不仅增强了模型的解决问题的能力,还提高了其答案的准确性和可靠性。 - 工具(Tools)
这一部分定义了LLM可用于获取额外信息或与外部环境交互的工具集。{tools}和{tool_names}作为参数传入,增加了模型操作的灵活性和适用性,使其能够根据具体情况选择最合适的工具来辅助解答。
该模板的设计理念在于通过明确的结构化指导和适当的工具使用,促使大型语言模型在解决复杂问题时表现出更高的效率和更强的准确度。通过引入迭代的“思考-行动-观察”机制,该框架不仅提升了模型的逻辑推理能力,还增强了其对外部信息的利用效率,从而在复杂问题解决过程中实现了高度的精确性和可靠性。