2、基于Langchain数仓智能问答
背景简介
在现代企业环境中,大量的数据被储存于分析型(OLAP)数据库系统中,用于数据分析和决策支持。然而,非技术背景的业务人员往往不具备使用SQL与数据库进行交互的技能。ChatGPT作为一个强大的语言模型,具备理解自然语言并生数据库SQL语句的能力。
LangChain作为连接大模型与各种系统的桥梁,它使用ChatGPT理解用户的自然语言查询,并基于数据库中Schema将这些查询转化为对应的SQL语句以与数据库进行交互。这样,用户可以通过简单的对话来检索、更新或操作数据库中的信息,从而提高了数据库的可访问性和用户的操作便捷性。
本篇将介绍如何基于Langchain实现对MySQL数据库的访问,并实现高度智能化的数据问答功能。
TPC-DS测试数据集
我们所使用的测试数据源自TPC-DS系统生成的测试数据集,TPC-DS是决策支持系统性能评估的重要标准之一,专为评估数据仓库、分布式数据库和大数据系统的性能而设计。TPC-DS的数据库模型包括24个精心设计的表,这些表模拟了一个典型的商业数据仓库环境。
下图是这个数据仓库的数据模型概览,这个模型涵盖了来自零售公司的各类业务数据,包括销售、库存、出货等多个关键业务领域,从而确保了在性能评估过程中的全面覆盖和准确模拟。这种丰富的数据模型为性能测试提供了有力支持,并能�够准确反映现实世界的复杂商业数据仓库情境。
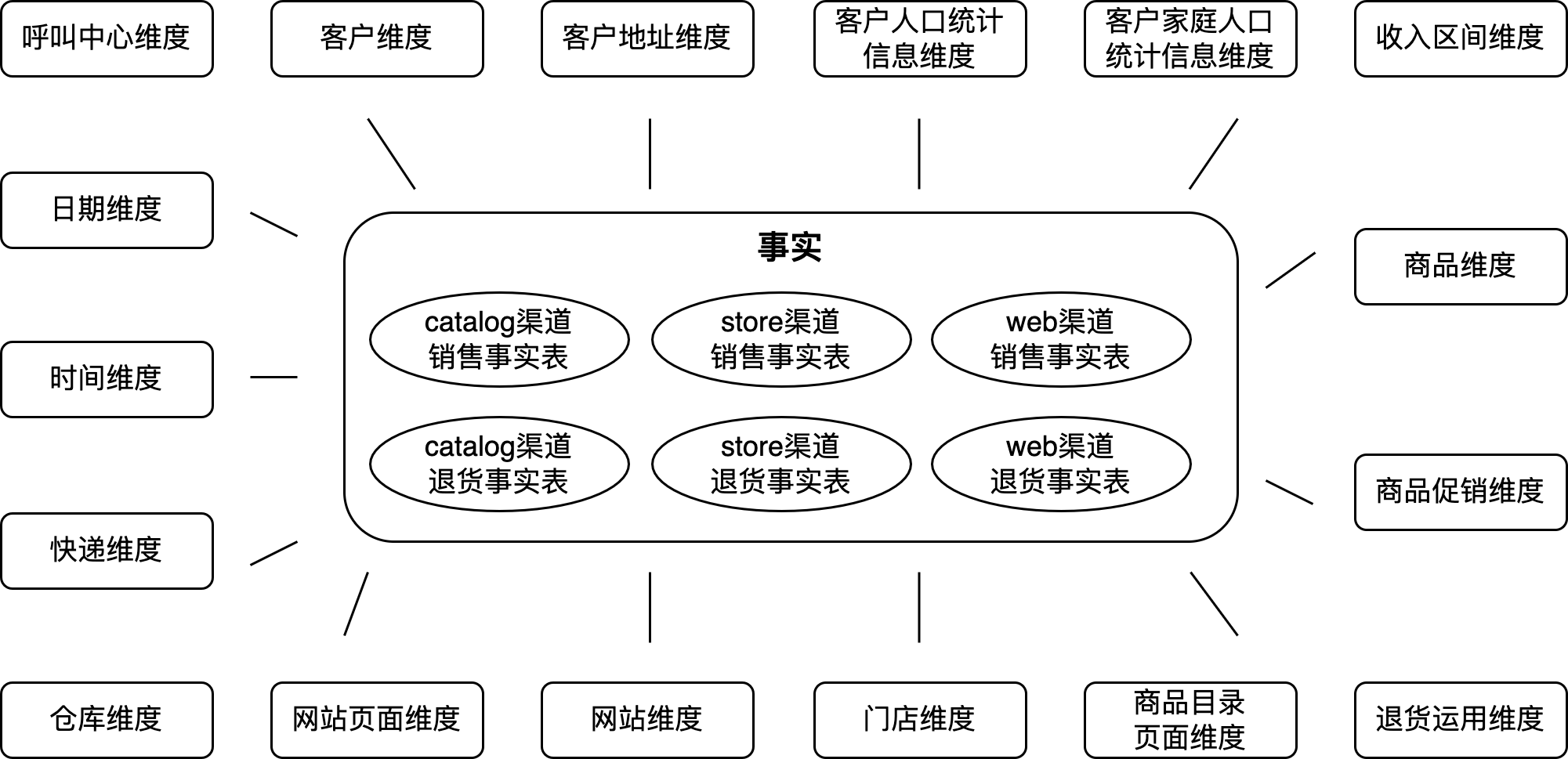
之所以选择了这个测试数据集,是为了后续全面验证大型模型在数据仓库中多种场景的性能表现,包括智能交互式数据分析、加工任务生成、指标加工口径梳理、以及数据血缘分析等实际生产应用场景。这样能够更深入地理解大型模型在数据仓库环境中的实际能力和潜力。
为了更好地理解本文的内容和后续讨论,我们建议读者阅读附带的文章:TPC-DS数据库Schema。该文章包含了详细的数据库表清单、数据字典、ER图等信息,了解这些信息有助于更好地理解实验结果。
此外,如果您需要更详尽的信息,建议您下载TPC-DS官方文档,该文档包含了标准规范和详细的技术要求,可在以下链接找到:TPC-DS官网文档: TPC BENCHMARK ™ DS Standard Specification。
代码实现
环境准备
首先,先安装LangChain以及其他所需依赖包, 这里mysql-connector-python和sqlalchemy是被用于连接mysql数据库。
%pip install --upgrade --quiet langchain langchain-community langchain-experimental langchain-openai mysql-connector-python sqlalchemy
下面是设置OpenAI的API_KEY,默认情况下我们使用OpenAI模型,当然也可以将其替换为其他模型。
import os
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
创建SQLDatabaseChain
以下代码是问答部分的核心代码,涉及创建了三个关键对象:
- OpenAI: 被SQLDatabaseChain使用用于和OpenAI进行交互,以实现自然语言和SQL的转换。
- SQLDatabase: 此对象用于数据库访问,负责处理与数�据库的查询执行以及数据检索等任务。
- SQLDatabaseChain: 是一个链式系统,它接受一个大型语言模型(LLM)对象以及SQLDatabase对象,旨在实现高度智能的自然语言与数据库之间的交互功能。
from langchain_openai import ChatOpenAI
from langchain_community.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
# 创建OpenAI模型对象
llm = ChatOpenAI(temperature=0, verbose=True)
# 创建数据库,分别在{user}、{password}、{host}、{database}中填入对应的账户号、密码、主机以及数据库
db = SQLDatabase.from_uri("mysql+pymysql://{user}:{password}@{host}/{database}")
# 创建DB Chain
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
通过Chain向数据库提问
我们用中文向数据库提第一个问题:
db_chain.invoke("一共有多少位顾客?")
首次提问便遇到“提交的消息的token数超过模型限制”的错误,如下图所示:
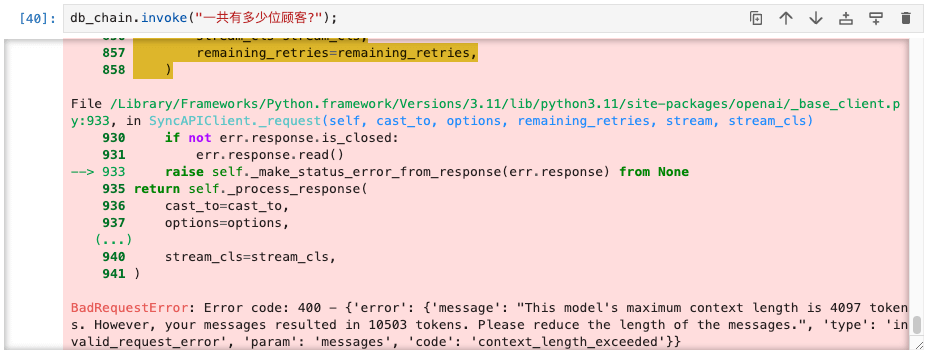
{
"error":{
"message":"This model's maximum context length is 4097 tokens. However, your > messages resulted in 10503 tokens. Please reduce the length of the messages.",
"type":"invalid_request_error",
"param":"messages",
"code":"context_length_exceeded"
}
}
原因是因为LangChain默认使用的模型为gpt-3.5-turbo,这个模型允许最大提交的token数是4096个,sqldbchain在向OpenAI提交请求的时候会把数据库相关的元数据关联信息一起提交,TPS-DB数据库总共24张表,元数据信息太大导致超出了限制,因此可以通过修改模型接受更大token来解决:
#在不设置模型的时候,默认会使用"gpt-3.5-turbo"
#llm = OpenAI(temperature=0, verbose=True)
#OpenAIm默认模型为gpt-3.5-turbo, 可以通过设置model_name参数来使用其他模型
llm = OpenAI(model_name="gpt-3.5-turbo-16k", temperature=0, verbose=True)
在更改模型后,SQLDatabaseChain的执行结果如下,主要包括提交给数据库的查询语句、查询的执行结果,以及经过OpenAI处理过的语义化的回答。我们看到生产的SQL代码非常准确,从客户表中获取所有的客户。
> Entering new SQLDatabaseChain chain...
一共有多少位顾客?
SQLQuery:SELECT COUNT(*) AS total_customers FROM customer
SQLResult: [(1000,)]
Answer:一共有1000位顾客。
> Finished chain.
LangChain提供了一个callback函数用来统计一次问答OpenAI的请求次数、所消耗的tokens数量以及相对应的费用。以下的代码示例演示了本次问答的统计数据:
from langchain.callbacks import get_openai_callback
with get_openai_callback() as cb:
db_chain.invoke("一共有多少位顾客?");
print(cb)
本次问答共消耗了超过2万多个tokens,所产生的费用为6美分。其中,主要的token消耗集中在提示词的token上,后续文章将详细解释为何需要如此多的token。
Tokens Used: 22485
Prompt Tokens: 22466
Completion Tokens: 19
Successful Requests: 2
Total Cost (USD): $0.067474
验证GPT对于数据库Schema的理解
我们持续对GPT进行提问,以获取排名前十的客户信息。这旨在评估在没有提供任何提示的情况下,GPT对数据库Schema的理解程度,以确定其是否能够准确返回答案:
db_chain.invoke("请返回购买金额最大的TOP10个客户姓名?");
根据GPT的返回结果我们可以观察到,GPT只从三个渠道的订单事实表中选择了Web渠道的订单进行统计,而没有统计所有渠道(catalog、store和web)的订单。在后续讨论中,我们将探讨如何借助提示词技术以提升GPT对Schema的理解,以实现更精确的结果返回。
> Entering new SQLDatabaseChain chain...
请返回购买金额最大的TOP10个客户姓名?
SQLQuery:SELECT c_first_name, c_last_name
FROM customer
ORDER BY (SELECT SUM(ws_sales_price)
FROM web_sales
WHERE ws_bill_customer_sk = c_customer_sk) DESC
LIMIT 10
SQLResult: [('Drew', 'Fuller'), ('Matthew', 'Nugent'), ('Angie', 'Washington'), ('Joseph', 'Fountain'), ('Ashley', 'Thompson'), ('Leonard', 'Munoz'), ('Lydia', 'Flores'), ('Brandi', 'Littlefield'), ('Amy', 'Quillen'), ('Stanton', 'Dallas')]
Answer:The top 10 customers with the highest purchase amount are:
1. Drew Fuller
2. Matthew Nugent
3. Angie Washington
4. Joseph Fountain
5. Ashley Thompson
6. Leonard Munoz
7. Lydia Flores
8. Brandi Littlefield
9. Amy Quillen
10. Stanton Dallas
> Finished chain.
结论
通过对数据仓库中GPT的问答进行初步测试,我们得出以下结论:
- 在复杂的数据仓库场景下,问答所需的上下文关联tokens数量非常大。
- GPT表现出卓越的数据库表Schema理解能力,然而,在缺乏提示词的情况下,仍然难以理解数据库Schema。
在接下来的篇章中,我们将深��入探讨SQLDatabaseChain的执行步骤和实现原理。